- 책 또는 웹사이트의 내용을 복제하여 다른 곳에 게시하는 것을 금지합니다.
- 책 또는 웹사이트의 내용을 발췌, 요약하여 강의 자료, 발표 자료, 블로그 포스팅 등으로 만드는 것을 금지합니다.
검색 서비스를 제공하는 CloudSearch
이재홍 http://www.pyrasis.com 2014.03.24 ~ 2014.06.30
CloudSearch는 대용량 데이터를 빠르게 검색할 수 있도록 검색 엔진을 제공해주는 서비스입니다.
30일 무료 평가 프로그램
CloudSearch는 검색 도메인 생성 후 30일 동안 무료로 사용할 수 있습니다.
문서 업로드 10,000건, IndexDocuments 요청 10건, 검색 인스턴스 750시간을 무료 사용할 수 있습니다. 무료 사용 시간을 모두 사용하거나 30일이 먼저 지나면 요금을 지불해야 합니다.
http://aws.amazon.com/ko/cloudsearch/free-trial/
대용량의 데이터를 처리 시간 없이 빠르게 검색하는 시스템을 구축하려면 데이터베이스 및 검색 전문가가 필요하고, 많은 시간과 비용이 소모됩니다. CloudSearch는 많은 서버와 검색 시스템을 구축하지 않아도 클릭 몇 번만으로 고성능 검색 엔진을 사용할 수 있습니다. 벤처기업 및 스타트업과 같은 작은 조직에서 유용합니다. 그리고 규모가 큰 대기업에서도 기존의 서버와 운영인력을 다른 곳에 활용할 수 있고, 비용을 절감할 수 있습니다.
CloudSearch에는 DynamoDB, RDS, S3를 이용하여 데이터를 올릴 수 있고, 데이터 형식은 PDF, MS 오피스(워드, 엑셀, 파워포인트), HTML, JSON, XML(RSS, ATOM), CSV를 지원합니다. 특별한 구조가 없는 일반 텍스트 파일도 사용할 수 있습니다.
CloudSearch는 구글처럼 봇이 웹사이트 데이터를 크롤링Crawling하는 방식이 아니라, 사용자가 직접 검색 도메인에 데이터를 넣어주어야 합니다.
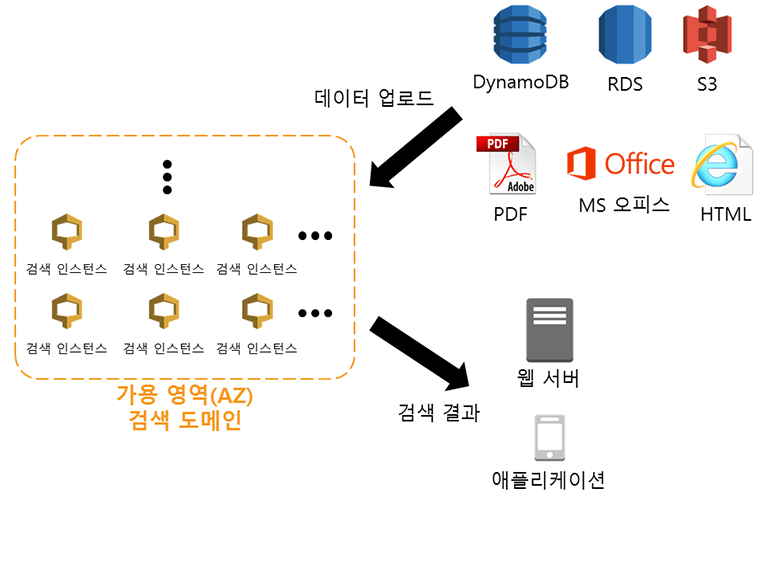 그림 25-1 CloudSearch 기본 개념도
그림 25-1 CloudSearch 기본 개념도
Apache Lucene은 오픈소스 검색 엔진 라이브러리이며, Apache Solr는 Apache Lucene을 사용한 엔터프라이즈용 검색 서버입니다. CloudSearch는 Apache Solr를 텍스트 검색 엔진으로 사용합니다. 그래서 CloudSearch의 검색 기술과 용어들은 Apache Lucene과 Apache Solr에서 사용하는 것들 입니다. RDS에서 MySQL, Oracle, SQL Server등을 사용하고, ElastiCache에서 Memcached와 Redis를 사용하는 것과 동일합니다.
http://lucene.apache.org/solr/
다음은 CloudSearch 기본 개념입니다.
- 검색 도메인(Domain): 검색 인스턴스의 집합이며 리전(Region)별로 생성해야 합니다. 데이터 업로드용 엔드포인트 URL과 검색용 엔드포인트 URL이 제공됩니다.
- 검색 인스턴스: 검색 인스턴스에서 데이터를 저장하고, 인덱싱하고, 검색 결과를 도출해냅니다. 검색 도메인이 속한 검색 인스턴스는 한 가용 영역(AZ)에만 생성됩니다. Multi-AZ 기능을 사용하면 다른 가용 영역에 검색 인스턴스들이 동일한 개수대로 복제됩니다.
- 검색 파티션(Partition): 검색 인스턴스당 검색 파티션이 하나씩 생성됩니다. 최대 10개까지 생성됩니다. 사용자가 임의로 추가하나 삭제할 수 없습니다.
- 필드(Field): 검색 엔진의 구조는 DB와 비슷합니다. 정형화된 데이터에서 개별 항목을 뜻합니다. 예) 영화 이름, 장르, 출연 배우, 감독, 제작사, 평점 등
- 필드 자료형: int, int-array, double, double-array, literal, literal-array, text, text-array, date, date-array, latlon(위도 경도 위치 정보)을 사용할 수 있습니다. text는 각 언어에 맞게 분석(형태소 분석 등)되는 자료형이고, literal은 분석되지 않고 있는 그대로 검색됩니다. 따라서 literal은 대소문자와 단어 등이 정확하게 일치해야 합니다.
- 패싯(Facet): 패싯 검색 기능은 검색 결과에서 항목 내용이 동일한 것들의 개수를 표시해주는 기능입니다. SQL의 Group By와 비슷합니다. 예) 자전거 검색을 했을 때 10
20만원짜리 10개, 2030만원짜리 5개 - Return: 검색 결과에 항목의 내용을 표시합니다.
- Sort: 항목을 정렬에 사용합니다.
- Highlight: 검색 결과에서 일치하는 문구에 강조 표시를 합니다.
- 문서(Document): 항목들이 모여 완전한 정보가 된 단위를 뜻합니다. 예) 인셉션, 타이타닉 등의 영화 정보
- 배치(Batch): 검색 도메인에 데이터를 올리는 단위입니다. 한 배치에는 여러 개의 문서가 포함될 수 있으며 최대 크기는 5MB 입니다.
- 인덱스(Index): 각 문서와 항목의 내용을 빠르게 찾을 수 있도록 검색 전용 데이터를 생성한 것이 인덱스 입니다(색인이라고도 하며 색인을 생성하는 작업을 인덱싱이라고 합니다).
- IndexDocuments 요청: 문서에 필드가 추가되어 문서 구조가 바뀔 경우, 인덱스를 다시 생성해야 합니다. 인덱스를 다시 생성하라는 요청을 IndexDocuments 요청이라고 합니다.
- Analysis Scheme: 필드 분석 방식을 설정합니다. 검색 엔진에서는 언어를 처리하는 방식이 가장 핵심입니다. 검색 질을 높일 수 있도록 Analysis Scheme에 불용어(Stopwords), 형태소 분석(Stemming), 동의어(Synonyms)를 추가할 수 있습니다.
- 요금: 검색 인스턴스 사용 시간, 배치 업로드 요청 개수, IndexDocuments 요청(데이터 용량), 데이터 전송 용량에 따라 책정됩니다. 자세한 요금은 AWS 사이트의 요금표(http://aws.amazon.com/ko/cloudsearch/pricing/)를 참조하기 바랍니다.
도메인(Domain)
CloudSearch에서 제공하는 검색 도메인은 인터넷에서 사용하는 도메인 네임(예: example.com)과는 다른 것입니다.
CloudSearch 검색 도메인에 데이터를 올리면 알아서 검색 인스턴스에 저장하고, 데이터 용량이 늘어나거나 검색 트래픽이 늘어나면 자동으로 검색 인스턴스 개수를 늘려줍니다. 그리고 Multi-AZ 기능을 사용하면 검색 도메인의 전체 검색 인스턴스가 다른 가용 영역에 복제됩니다. 따라서 장애가 발생해도 자동적으로 예비 검색 도메인을 사용하게 되므로 정상적인 서비스를 제공 할 수 있습니다.
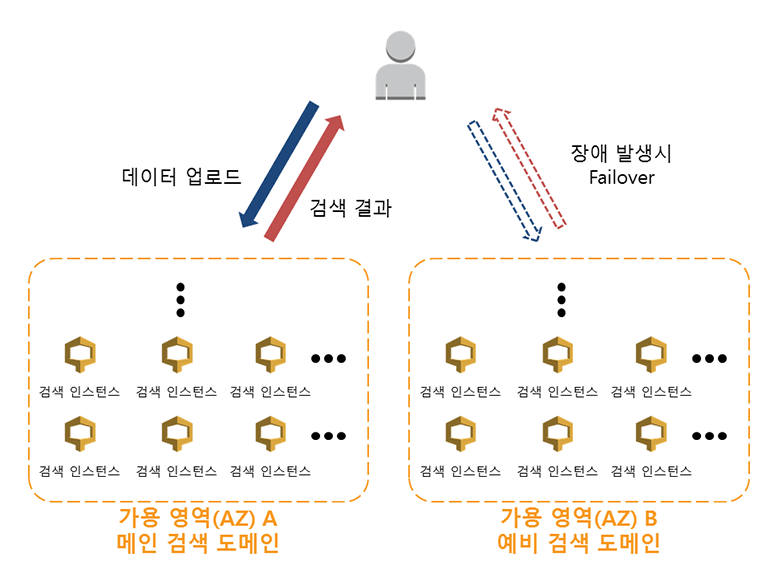 그림 25-2 CloudSearch 검색 인스턴스 자동 확장과 장애 대응(Multi-AZ)
그림 25-2 CloudSearch 검색 인스턴스 자동 확장과 장애 대응(Multi-AZ)
Multi-AZ 기능과 비용
Multi-AZ 기능을 사용하면 검색 인스턴스의 개수가 2배가 되므로 검색 인스턴스에 대한 요금을 더 지불해야 합니다.





저작권 안내
이 웹사이트에 게시된 모든 글의 무단 복제 및 도용을 금지합니다.- 블로그, 게시판 등에 퍼가는 것을 금지합니다.
- 비공개 포스트에 퍼가는 것을 금지합니다.
- 글 내용, 그림을 발췌 및 요약하는 것을 금지합니다.
- 링크 및 SNS 공유는 허용합니다.